library(readr)
library(tidyr)
library(dplyr)
##
## 次のパッケージを付け加えます: 'dplyr'
## 以下のオブジェクトは 'package:stats' からマスクされています:
##
## filter, lag
## 以下のオブジェクトは 'package:base' からマスクされています:
##
## intersect, setdiff, setequal, union
library(stringr)
library(lubridate)
##
## 次のパッケージを付け加えます: 'lubridate'
## 以下のオブジェクトは 'package:base' からマスクされています:
##
## date, intersect, setdiff, union中央省庁のオープンデータには印刷を前提としたフォーマットのものをそのままExcel形式やCSV形式で公開していて、いわゆる雑然データ(messy data)となっているというものがままあります。今回はそのひとつを整然データ(tidy data)に整形する過程をご紹介します。
はじめに
今回の題材には、環境省が公開している越前岬測定所の2009年における空間放射線量率測定結果(1時間値)の確定値から1時間値_CSVファイル(ライセンスはCC-BY)をもちいました。データは以下のようになっています。

1日のデータが12行にわたっていて、その各行が測定項目4つの最大値・最小値・平均値となっています。そして、4列目以降が各月の値という、複雑な構造となっています。
また、図では見えていませんが、下の方、2月・4月の31日など存在しない日の値には“−”が入っています。
これを以下のように整形したいと思います。
| Date | α濃度_最大値 | α濃度_最小値 | α濃度_平均値 | β濃度_最大値 | … |
|---|---|---|---|---|---|
| 2009-01-01 | 0.75 | 0.25 | 0.47 | 1.09 | … |
| 2009-01-02 | 0.53 | 0.38 | 0.47 | 0.81 | … |
| 2009-01-03 | 0.38 | 0.32 | 0.35 | 0.58 | … |
| : | : | : | : | : |
準備
使用するライブラリをよみこみます。library(tidyverse)とすると1行ですむので、tidyverseを全部インストールしている方はそちらのほうが簡単でしょう。
データよみこみ
まずはCSVファイルをよみこみます。文字コードはシフトJISなので、locale(encoding = "CP932")と引数をあたえます。
1行目はメタデータなのでよまず、2行目の列名もよまないことにします(skip = 2)。2〜3行目が空白になっていたりするので、列名は明示的に指定することにします(col_names = c("Day", "Var", "Stat", str_c("m", 1:12)))。4列目以降の数値データも、下の方に文字が混ざっているので、ここでは文字列としてよみこみます(col_types = str_dup("c", 15))。
data_file <- "181_AB_01s_2009.csv"
d0 <- read_csv(data_file, skip = 2,
locale = locale(encoding = "CP932"),
col_names = c("Day", "Var", "Stat",
str_c("m", 1:12)),
col_types = str_dup("c", 15))
head(d0)
## # A tibble: 6 × 15
## Day Var Stat m1 m2 m3 m4 m5 m6 m7 m8 m9 m10
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 1 空気… 最大値 0.75 0.51 0.55 0.67 0.82 <NA> 0.88 0.84 0.28 0.70
## 2 <NA> <NA> 最小値 0.25 0.31 0.37 0.28 0.30 <NA> 0.38 0.43 0.16 0.54
## 3 <NA> <NA> 平均値 0.47 0.40 0.47 0.48 0.54 <NA> 0.63 0.61 0.22 0.64
## 4 <NA> 空気… 最大値 1.09 0.71 0.90 1.00 1.07 <NA> 1.33 1.25 0.43 1.14
## 5 <NA> <NA> 最小値 0.39 0.45 0.58 0.43 0.43 <NA> 0.55 0.66 0.24 0.86
## 6 <NA> <NA> 平均値 0.71 0.57 0.76 0.72 0.75 <NA> 0.91 0.93 0.34 1.01
## # ℹ 2 more variables: m11 <chr>, m12 <chr>データ整形
ここからデータを整形していきます。
まず、1列目(日)と2列目(項目名)は、上と同じ値のところが空白になっていますので、これに値を与えます。処理後のデータの先頭6行を表示します。
d1 <- d0 |>
tidyr::fill(Day:Var, .direction = "down")
head(d1)
## # A tibble: 6 × 15
## Day Var Stat m1 m2 m3 m4 m5 m6 m7 m8 m9 m10
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 1 空気… 最大値 0.75 0.51 0.55 0.67 0.82 <NA> 0.88 0.84 0.28 0.70
## 2 1 空気… 最小値 0.25 0.31 0.37 0.28 0.30 <NA> 0.38 0.43 0.16 0.54
## 3 1 空気… 平均値 0.47 0.40 0.47 0.48 0.54 <NA> 0.63 0.61 0.22 0.64
## 4 1 空気… 最大値 1.09 0.71 0.90 1.00 1.07 <NA> 1.33 1.25 0.43 1.14
## 5 1 空気… 最小値 0.39 0.45 0.58 0.43 0.43 <NA> 0.55 0.66 0.24 0.86
## 6 1 空気… 平均値 0.71 0.57 0.76 0.72 0.75 <NA> 0.91 0.93 0.34 1.01
## # ℹ 2 more variables: m11 <chr>, m12 <chr>pivot_longで、各月の値を1列にいれ、Month列に月の値がはいるようにします。
d2 <- d1 |>
tidyr::pivot_longer(cols = m1:m12, names_to = "Month")
head(d2)
## # A tibble: 6 × 5
## Day Var Stat Month value
## <chr> <chr> <chr> <chr> <chr>
## 1 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m1 0.75
## 2 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m2 0.51
## 3 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m3 0.55
## 4 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m4 0.67
## 5 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m5 0.82
## 6 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 m6 <NA>Month列の接頭辞の”m“をけずります。
d3 <- d2 |>
dplyr::mutate(Month = str_sub(Month, 2))
head(d3)
## # A tibble: 6 × 5
## Day Var Stat Month value
## <chr> <chr> <chr> <chr> <chr>
## 1 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 1 0.75
## 2 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 2 0.51
## 3 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 3 0.55
## 4 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 4 0.67
## 5 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 5 0.82
## 6 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 6 <NA>存在しない日(value == "−" )の行を削ります。ただし、欠測のNAの行はのこします。ここでは最後の6行を表示しています。
d4 <- d3 |>
dplyr::filter(value != "−" | is.na(value))
tail(d4)
## # A tibble: 6 × 5
## Day Var Stat Month value
## <chr> <chr> <chr> <chr> <chr>
## 1 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 3 5.55
## 2 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 5 <NA>
## 3 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 7 16.54
## 4 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 8 9.10
## 5 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 10 21.44
## 6 31 空気中放射能濃度(β濃度)[Bq/m3](2ステップ後) ×1000 平均値 12 6.12value列が数値データだけになったので、数値型に変換します。変換後は列の型が<dbl>になっています。
d5 <- d4 |>
dplyr::mutate(value = as.numeric(value))
head(d5)
## # A tibble: 6 × 5
## Day Var Stat Month value
## <chr> <chr> <chr> <chr> <dbl>
## 1 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 1 0.75
## 2 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 2 0.51
## 3 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 3 0.55
## 4 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 4 0.67
## 5 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 5 0.82
## 6 1 空気中放射能濃度(α濃度)[Bq/m3](集じん中) 最大値 6 NAつぎに、pivot_widerをつかって、測定項目名と統計量名の組み合わせを新しい列にします。
d6 <- d5 |>
tidyr::pivot_wider(names_from = c(Var, Stat),
values_from = value)
head(d6)
## # A tibble: 6 × 14
## Day Month 空気中放射能濃度(α濃度)[Bq/m3](集じん中)…¹ 空気中放射能濃度(α濃…²
## <chr> <chr> <dbl> <dbl>
## 1 1 1 0.75 0.25
## 2 1 2 0.51 0.31
## 3 1 3 0.55 0.37
## 4 1 4 0.67 0.28
## 5 1 5 0.82 0.3
## 6 1 6 NA NA
## # ℹ abbreviated names: ¹`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最大値`,
## # ²`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最小値`
## # ℹ 10 more variables: `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最大値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最小値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(α濃度)[Bq/m3](2ステップ後) ×1000_最大値` <dbl>, …年は2009なので、これとMonthとDateとをくみあわせて、日付のデータをつくります。これをDate列とします。
d7 <- d6 |>
dplyr::mutate(Date = ymd(str_c("2009", Month, Day, sep = "/")))
head(d7)
## # A tibble: 6 × 15
## Day Month 空気中放射能濃度(α濃度)[Bq/m3](集じん中)…¹ 空気中放射能濃度(α濃…²
## <chr> <chr> <dbl> <dbl>
## 1 1 1 0.75 0.25
## 2 1 2 0.51 0.31
## 3 1 3 0.55 0.37
## 4 1 4 0.67 0.28
## 5 1 5 0.82 0.3
## 6 1 6 NA NA
## # ℹ abbreviated names: ¹`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最大値`,
## # ²`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最小値`
## # ℹ 11 more variables: `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最大値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最小値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(α濃度)[Bq/m3](2ステップ後) ×1000_最大値` <dbl>, …Dateと各測定項目+統計量の列だけ残します。
d8 <- d7 |>
dplyr::select(Date, where(is.numeric))
head(d8)
## # A tibble: 6 × 13
## Date 空気中放射能濃度(α濃度)[Bq/m3](集じん中)_…¹ 空気中放射能濃度(α濃…²
## <date> <dbl> <dbl>
## 1 2009-01-01 0.75 0.25
## 2 2009-02-01 0.51 0.31
## 3 2009-03-01 0.55 0.37
## 4 2009-04-01 0.67 0.28
## 5 2009-05-01 0.82 0.3
## 6 2009-06-01 NA NA
## # ℹ abbreviated names: ¹`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最大値`,
## # ²`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最小値`
## # ℹ 10 more variables: `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最大値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最小値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(α濃度)[Bq/m3](2ステップ後) ×1000_最大値` <dbl>, …arrangeでDateの順に並べかえます。これで完成です。
d9 <- d8 |>
dplyr::arrange(Date)
head(d9)
## # A tibble: 6 × 13
## Date 空気中放射能濃度(α濃度)[Bq/m3](集じん中)_…¹ 空気中放射能濃度(α濃…²
## <date> <dbl> <dbl>
## 1 2009-01-01 0.75 0.25
## 2 2009-01-02 0.53 0.38
## 3 2009-01-03 0.38 0.32
## 4 2009-01-04 0.36 0.33
## 5 2009-01-05 0.72 0.3
## 6 2009-01-06 0.42 0.27
## # ℹ abbreviated names: ¹`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最大値`,
## # ²`空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最小値`
## # ℹ 10 more variables: `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最大値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_最小値` <dbl>,
## # `空気中放射能濃度(β濃度)[Bq/m3](集じん中)_平均値` <dbl>,
## # `空気中放射能濃度(α濃度)[Bq/m3](2ステップ後) ×1000_最大値` <dbl>, …まとめると
ここまで説明のため、処理ごとに結果を新しいオブジェクトに代入していましたが、パイプをつかって一気に処理すると以下のようになります。
data <- read_csv(data_file, skip = 2,
locale = locale(encoding = "CP932"),
col_names = c("Day", "Var", "Stat",
str_c("m", 1:12)),
col_types = str_dup("c", 15)) |>
tidyr::fill(Day:Var, .direction = "down") |>
tidyr::pivot_longer(cols = m1:m12, names_to = "Month") |>
dplyr::mutate(Month = str_sub(Month, 2)) |>
dplyr::filter(value != "−" | is.na(value)) |>
dplyr::mutate(value = as.numeric(value)) |>
tidyr::pivot_wider(names_from = c(Var, Stat),
values_from = value) |>
dplyr::mutate(Date = ymd(str_c("2009", Month, Day, sep = "/"))) |>
dplyr::select(Date, where(is.numeric)) |>
dplyr::arrange(Date)グラフ
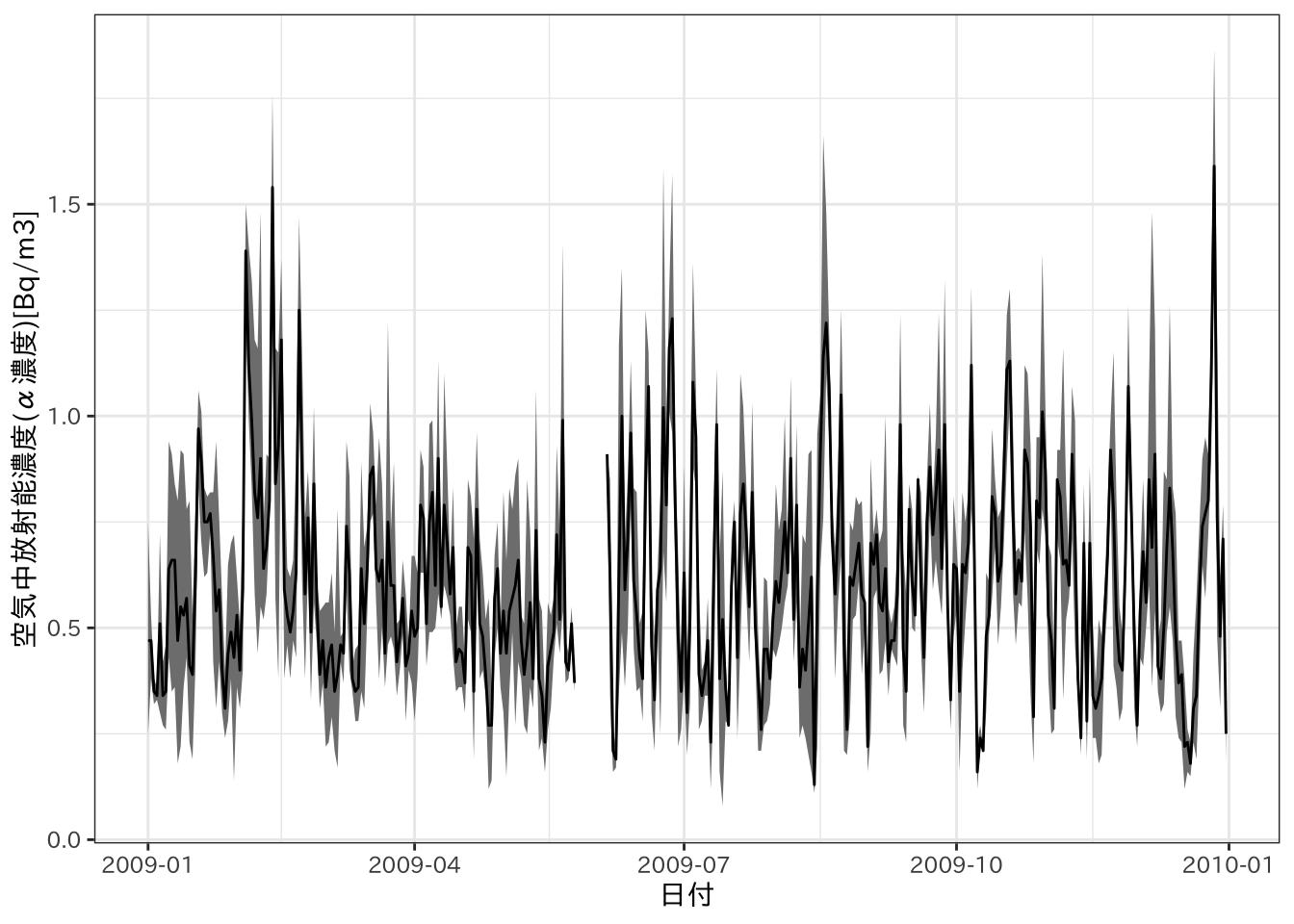
これでggplot2でもあつかいやすくなりました。
library(ggplot2)
ggplot(data, aes(x = Date)) +
geom_ribbon(aes(ymin = `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最小値`,
ymax = `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_最大値`),
fill = "gray50") +
geom_line(aes(y = `空気中放射能濃度(α濃度)[Bq/m3](集じん中)_平均値`)) +
scale_x_date(date_labels = "%Y-%m") +
labs(x = "日付", y = "空気中放射能濃度(α濃度)[Bq/m3]") +
theme_bw(base_family = "IPAexGothic")