library(duckplyr)
## 要求されたパッケージ dplyr をロード中です
##
## 次のパッケージを付け加えます: 'dplyr'
## 以下のオブジェクトは 'package:stats' からマスクされています:
##
## filter, lag
## 以下のオブジェクトは 'package:base' からマスクされています:
##
## intersect, setdiff, setequal, union
## The duckplyr package is configured to fall back to dplyr when it encounters an
## incompatibility. Fallback events can be collected and uploaded for analysis to
## guide future development. By default, data will be collected but no data will
## be uploaded.
## ℹ Automatic fallback uploading is not controlled and therefore disabled, see
## `?duckplyr::fallback()`.
## ✔ Number of reports ready for upload: 4.
## → Review with `duckplyr::fallback_review()`, upload with
## `duckplyr::fallback_upload()`.
## ℹ Configure automatic uploading with `duckplyr::fallback_config()`.
## ✔ Overwriting dplyr methods with duckplyr methods.
## ℹ Turn off with `duckplyr::methods_restore()`.Tokyo.R 113 でのeitsupiさんの発表「duckplyr覚醒!」で紹介されていたduckplyrをためしてみました。
duckplyrとは、SQLではなくdplyrの文法でDuckDBを使えるというもののようです。Parquetの読み書きにも対応しています。
Parquetといえば、先日の Japan.R 2024 での Hadley Wickham のプレゼンテーションでも

みたいなスライドがあったところです。
【2025-02-10 追記】記事を公開したところで、BlueskyにてYutaniさんからコメントをいただきました。要点は以下の2点です。
「as.factor したところで「## duckplyr: materializing」と出力されていて、その時点でふつうの tibble に変換されてしまってそれ以後はDuckDB は使われていないと思います。」
「あと、ちょうど先週 duckplyr は 1.0.0 に上がったんですが、その際に dplyr の関数を export するのをやめたみたいです。つまり、duckplyr::filter() などは消えていて、dplyr::* を使ってくれ、とのことです」
それから、version 1.0.0では、df_from_csvやdf_to_parquet, df_from_parquetなんかもdepricatedになっていました。それぞれ、read_csv_duckdb, compute_parquet, read_parquet_duckdbを使ってくれ、とのことです。
ということで、version 1.0.0に対応して修正しました。
準備
duckplyrはCRANからインストールできます。インストール方法や基本的な使い方は、GitHubのtidyverse/duckplyrに説明があります。
データの読み書き
今回の試用では、以前「RでParquetの読み書き」で使用した植生被度データをつかってみました。
Itô, Hiroki (2018). Data on forest regeneration after catastrophic windthrow in the headwater region of the Ishikari River, Hokkaido, Japan. figshare. Dataset. doi:10.6084/m9.figshare.6442796.v3
まずはテキストファイルをダウンロードして、テンポラリファイルに保存します。
library(curl)
## Using libcurl 8.7.1 with LibreSSL/3.3.6
url <- "https://figshare.com/ndownloader/files/22237545"
tsv_file <- tempfile("cover.tsv")
curl(url) |>
readLines() |>
writeLines(file(tsv_file))ダウンロードしたファイルはタブ区切りテキストファイルですが、duckplyrのdf_from_csvread_csv_duckdb関数で読み込めます。読み込んだら、データのクラスを確認してみます。
cover_data <- read_csv_duckdb(tsv_file)
class(cover_data)
## [1] "prudent_duckplyr_df" "duckplyr_df" "tbl_df"
## [4] "tbl" "data.frame"読み込んだデータを確認します。
head(cover_data, 10)
## # A duckplyr data frame: 8 variables
## Belt Quadrat Layer Year Date Scientific_name Japanese_name Cover
## <dbl> <dbl> <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 27 1 canopy 1980 1980-09 Betula platyphylla… シラカンバ 5
## 2 27 1 canopy 1984 1984-09 Betula platyphylla… シラカンバ 5
## 3 27 1 canopy 1988 1988-09-13 Betula platyphylla… シラカンバ 5
## 4 27 1 canopy 1988 1988-09-13 Betula ermanii ダケカンバ 1
## 5 27 1 canopy 1998 1998-07-23 Betula platyphylla… シラカンバ 5
## 6 27 1 canopy 1998 1998-07-23 Betula ermanii ダケカンバ 2
## 7 27 1 canopy 1998 1998-07-23 Abies sachalinensis トドマツ +
## 8 27 1 canopy 2002 2002-07-30 Abies sachalinensis トドマツ +
## 9 27 1 canopy 2002 2002-07-30 Betula platyphylla… シラカンバ 5
## 10 27 1 canopy 2002 2002-07-30 Betula ermanii ダケカンバ 2読み込んだデータをParquetで書き出します。これにはdf_to_parquetcompute_parquet関数を使用できます。
parquet_file <- tempfile("cover_data.parquet")
cover_data |>
compute_parquet(parquet_file)
## # A duckplyr data frame: 8 variables
## Belt Quadrat Layer Year Date Scientific_name Japanese_name Cover
## <dbl> <dbl> <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 27 1 canopy 1980 1980-09 Betula platyphylla… シラカンバ 5
## 2 27 1 canopy 1984 1984-09 Betula platyphylla… シラカンバ 5
## 3 27 1 canopy 1988 1988-09-13 Betula platyphylla… シラカンバ 5
## 4 27 1 canopy 1988 1988-09-13 Betula ermanii ダケカンバ 1
## 5 27 1 canopy 1998 1998-07-23 Betula platyphylla… シラカンバ 5
## 6 27 1 canopy 1998 1998-07-23 Betula ermanii ダケカンバ 2
## 7 27 1 canopy 1998 1998-07-23 Abies sachalinensis トドマツ +
## 8 27 1 canopy 2002 2002-07-30 Abies sachalinensis トドマツ +
## 9 27 1 canopy 2002 2002-07-30 Betula platyphylla… シラカンバ 5
## 10 27 1 canopy 2002 2002-07-30 Betula ermanii ダケカンバ 2
## # ℹ more rows念のためcover_dataオブジェクトを消去して、df_from_parquetread_parquet_duckdb関数で先ほど書き出したParquetファイルを読み込みます。
現在のduckplyr (version 0.4.11.0.0) ではParquet形式でのfactor型の書き出しはまだうまくいかないようなので、今回は文字列として書き出して、読み込んでいます。as.factorでfactor型に変換するとDuckDBが使われなくなるとのことですので、character型のままにしています。
rm("cover_data")
cover_data <- read_parquet_duckdb(parquet_file) #|>
# dplyr::mutate_at(c("Belt", "Quadrat", "Layer", "Cover"), as.factor)データの操作
Scientific_nameが”Abies sachalinensis”(シラカンバ)の行を抜き出して、BeltとYearごとに全部でいくつのデータがあるのかを数えるということをやってみました。データとしてはあんまり意味がありませんが、まあひとつの例です。
duckplyr::とつけていたのですが、エクスポートが廃止されたとのことでこれを削除しました。
cover_data |>
filter(Scientific_name == "Abies sachalinensis") |>
summarise(.by = c("Belt", "Year"), num = n()) |>
arrange(Belt, Year)
## # A duckplyr data frame: 3 variables
## Belt Year num
## <dbl> <dbl> <int>
## 1 27 1957 1
## 2 27 1958 2
## 3 27 1959 2
## 4 27 1960 2
## 5 27 1961 2
## 6 27 1962 2
## 7 27 1963 2
## 8 27 1964 4
## 9 27 1965 2
## 10 27 1966 2
## # ℹ more rowsグラフもつくってみます。Belt 27の林冠層(conopy)のシラカンバ(Abies sachalinensis)について、方形区(Quadrat)ごとの被度階級(Class)の年変化をタイルで表示します。
library(ggplot2)
cover_data |>
filter(Belt == "27",
Layer == "canopy",
Scientific_name == "Abies sachalinensis") |>
ggplot(aes(x = Year, y = Quadrat, fill = Cover)) +
geom_tile(height = 1, width = 1) +
scale_fill_brewer(palette = "BrBG") +
labs(title = "Abies sachalinensis: Belt 27") +
theme_bw()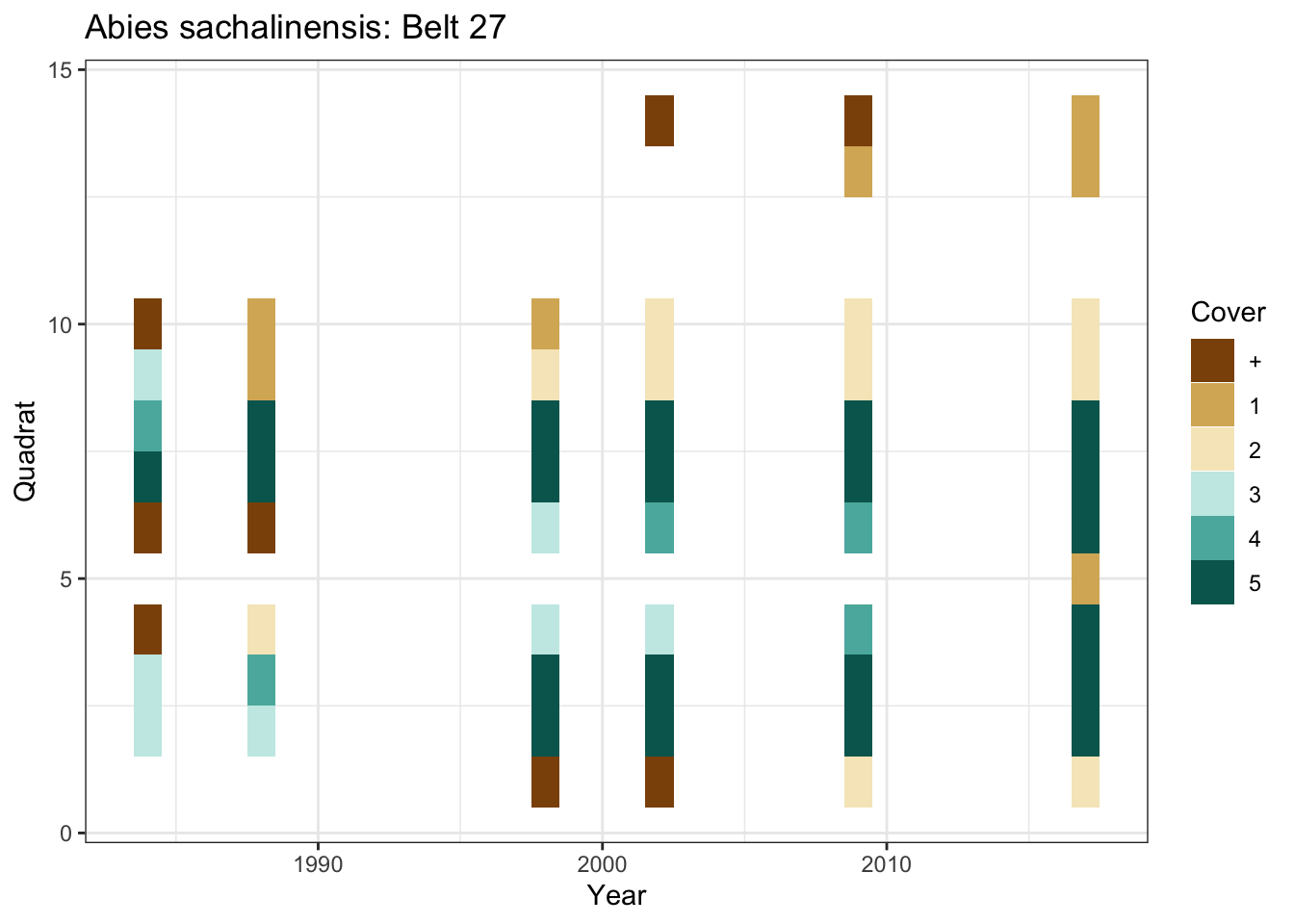
本来なら、見つからなかったところ(1998年のQuadrat 11〜14とか)と、そもそも測定していないところとを区別したほうがよいのですが、ここでは手抜きをしています。
おわりに
duckplyrをつかう理由としては、たぶん速さが一番になるかと思いますが、今回はそんなに大きなデータではためしていません。いずれそういう場合が訪れたときのためにメモしておきました。
めでたくversion 1.0.0となりましたので、これで基本的な仕様はかたまったことでしょう。