library(data.table)
library(tidyverse)
library(nanoparquet)
library(jpmesh)
data_files <-
c("bear_incidents_forest_r1-r6.csv",
"bear_incidents_river_r1-r6.csv",
"bear_incidents_attractants_r1-r6.csv",
"bear_incidents_young_bears_r1-r6.csv",
"bear_incidents_mass_outbreak_r2.csv")「クマ×共生ハッカソン ~あなたのアイデアが石川の安全を変える~ 第1回 課題発見編」(石川県・金沢市共催)に参加することにしました。このイベントに向けて、石川県のクマ出没データがnoteの記事「クマ共生ハッカソンに向けたインプット情報とデータのご紹介 ―石川県発、「共助×データ連携」で考える人とクマの未来― 」にて公開されています。そこで、このデータを利用していこうと思いますが、まずはデータの前処理が必要でしたので、その過程を記録しておきます。
【2025-07-28 追記】 データが「いしかわオープンデータカタログ」の「石川県クマ出没データ」にて公開されるようになりましたので、そちらのデータを使用するようにしました。これにあわせて本文も大幅に修正しました。
準備
「石川県クマ出没データ」にある「石川県クマ出没分析マップ」のデータ(1)〜(5)のCSVファイルをダウンロードしておきます。「R7 ツキノワグマ目撃・痕跡情報- R7目撃情報」は、データ構造が違うので、今回は扱っていません。
Rのパッケージの読み込みと、データファイルの指定をおこないます。
データ読み込み
データを読み込んで、処理をおこなう関数を定義します。
ここでは以下の処理をおこないます。
出没年を西暦に直します出没日を日付型にします頭数を整数型にしますIDを「出没年+ID」にします(年をまたいでも重複しないように)- 一部メッシュコードが誤っているところや、空白になっているところがありました。jpmeshパッケージを利用して500mメッシュコードを補完します。
- さらに文字型に変換します。
read_fun <- function(file_path) {
col_types <- str_c(str_dup("c", 13), str_dup("d", 3))
data.table::fread(file_path, header = TRUE) |>
dplyr::mutate(
`出没年` = as.numeric(str_sub(`出没年`, 2)) + 2018,
`出没日` = case_when(
# 無記入の場合、欠損値に
`出没日` == "" ~ as.Date(NA),
# Excelのシリアル値の場合
str_detect(`出没日`, "^4[0-9]{4}$") ~
as.Date(as.numeric(`出没日`, tz = "Asia/Tokyo"),
origin = "1899-12-30"),
# "R1..."という形式の場合
str_detect(`出没日`, "^R[1-9]") ~
str_replace(`出没日`, "^R[1-9]",
as.character(`出没年`)) |>
ymd(tz = "Asia/Tokyo"),
# "2019...""という形式の場合
str_detect(`出没日`, "^2[0-9]{3}") ~
ymd(`出没日`, tz = "Asia/Tokyo"),
# その他は欠損値に
TRUE ~ as.Date(NA)),
# 頭数を整数に変換, エラーになるものは個別に対処
`頭数` = if_else(!is.na(as.integer(`頭数`)),
# 変換が成功するとき
as.integer(`頭数`),
# 変換が失敗するとき
case_match(
`頭数`,
c("1", "1頭", "1頭", "不明(1か2)",
"体長1m程度と推定される成獣",
"成獣1頭") ~ 1,
c("2〜3頭", "2頭") ~ 2,
c("3頭") ~ 3,
c("4〜5頭", "4頭") ~ 4,
.default = as.integer(NA))),
# ID <- 年 + ID
ID = str_c(`出没年`, ID, sep = "-"),
# 500mメッシュコードは、jpmesh::coords_to_mesh()を使用して、
# 経度・緯度から計算し直します。
`500mメッシュコード` = coords_to_mesh(`経度`, `緯度`,
to_mesh_size = 0.5) |>
as.character()
) |>
as_tibble()
}データファイルをまとめてリストdata_tに読み込みます。
# case_matchではいったん各要素を評価するので警告がでますが
# これは問題ではありません。
data_t <- purrr::map(
data_files,
\(f) read_fun(file.path("data", f))
)data_tリストの各要素は、出没タイプ(「森林からの出没」、「河川からの出没」、「誘引物が原因の出没」、「誘引物が原因の出没」、「大量出没年に特有の出没」)でわけたデータとなっていますが、これをひとつのデータフレームにまとめたいと思います。出没タイプごとのデータ間には重複がありますので、IDをつかって、重複を除くように処理します。
具体的には、
data_tリストに含まれるデータフレームをbind_rows関数で縦につなげたうえで、- 出没タイプの列はいったん除いておいて、
distinct関数でIDの重複を除いてから、- 各行に、出没タイプの列を加えるようにしました。
出没タイプはNAならFALSE、それ以外(基本的に1が入っています)はTRUEにします。
data <- data_t |>
dplyr::bind_rows() |>
dplyr::select(1:15) |>
dplyr::distinct(ID, .keep_all = TRUE) |>
dplyr::left_join(dplyr::select(data_t[[1]], c(2, 16)), by = "ID") |>
dplyr::left_join(dplyr::select(data_t[[2]], c(2, 16)), by = "ID") |>
dplyr::left_join(dplyr::select(data_t[[3]], c(2, 16)), by = "ID") |>
dplyr::left_join(dplyr::select(data_t[[4]], c(2, 16)), by = "ID") |>
dplyr::left_join(dplyr::select(data_t[[5]], c(2, 16)), by = "ID") |>
dplyr::mutate_at(16:20, \(x) !is.na(x))出没日がdatetime型になっているので、Date型にします。
data <- data |>
dplyr::mutate(`出没日` = as.Date(`出没日`, tz = "Asia/Tokyo"))データ出力
まとめたデータをParquetファイルに出力します。
write_parquet(data, file = file.path("outputs", "kuma_data.parquet"))グラフ作成
出力したParquetファイルを利用して、グラフを作成してみます。
まず、これまでのオブジェクトをいったんすべて削除します。
rm(list = ls())Parquetファイルからデータを読み込みます。
data <- read_parquet(file.path("outputs", "kuma_data.parquet"))年ごとの出没情報数を棒グラフにしてみます。
ggplot(data, aes(x = `出没年`)) +
geom_bar() +
labs(title = "石川県のクマ出没情報", x = "年", y = "件数") +
scale_x_continuous(breaks = 2019:2024,
minor_breaks = NULL) +
theme_bw(base_family = "Noto Sans JP", base_size = 14)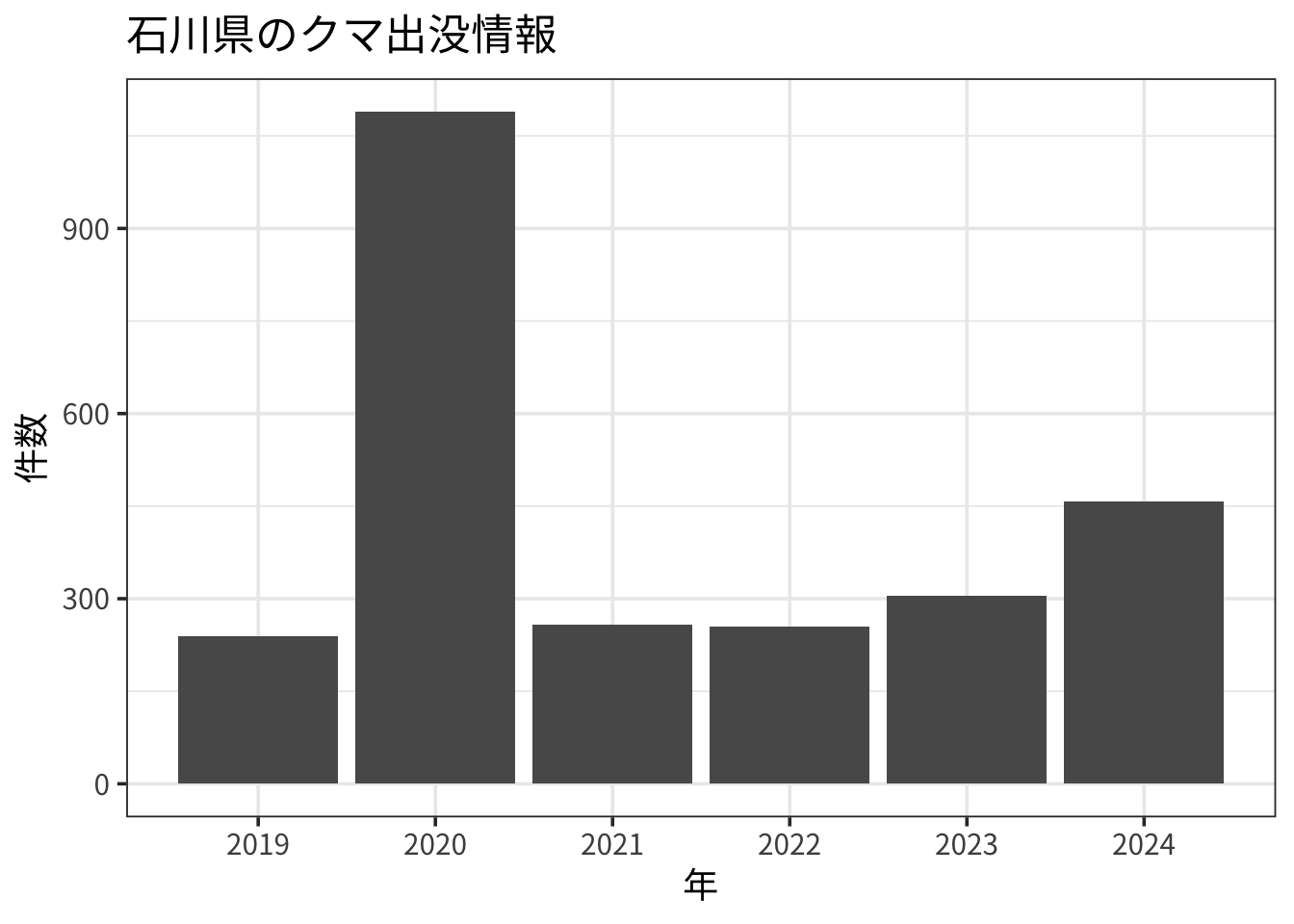
2019年以降では2020年が最も出没情報の件数が多かったことがわかります。